AWS Solution Architect certification
The AWS Certified Solutions Architect certification offered by Amazon Web Services (AWS) designed to validate an
individual's expertise in designing resilient, high-performing, secure, and cost-efficient architect on the AWS platform and services.
AWS maintains over 30% of market share of the global cloud computing sector according to data in 2023. Obtaining AWS solution architect certification not
only enhance your cloud knowledge but equips you to design better solution meet SLA and lower TCO.
How do I prepare
My experience in cloud computing spans several years in working closely with customers on both on-premises and hybrid-cloud environments. This has provided me
with a solid foundational knowledge of Storage, Network, Compute instances, VMs, and more. However, the vast array of over 200 AWS services can initially seem
overwhelming. The "Ultimate AWS Certified Solution Architect Associate SAA-C03" course on Udemy, taught by Stephane Maarek, was instrumental in helping me navigate
these services. Stephane's clear and structured explanations of AWS services make them easily understandable. The course's hands-on labs encourage practical engagement,
ensuring concepts are not only learned but fully grasped.
After grasping the technical concepts of each service, it's beneficial to develop a holistic architectural perspective, linking services together to meet
specific requirements. For instance, integrating Kinesis Data Streams and Kinesis Data Firehose to ingest real-time data into S3 bucket for analysis. Akin
to connecting LEGO pieces, each service interlocks to build a comprehensive solution. Resources like the AWS blog
and the AWS Architecture Center have valuable material to reference and establish holistic view.
The AWS Skill Builder offers practice exams that are instrumental in familiarizing yourself with the
format and types of questions you'll encounter. Similar practice exams are available on Udemy as well. Aim to score above 800 on your practice exam,
review your answers, and take notes on the practice exams to solidify your understanding and readiness for the actual exam.
Exam experience
The exam lasts 130 minutes and costs $150. It comprises 65 questions, which are either multiple-choice to select one correct answer out of four
or multiple-response where two or more answers must be selected from five options. There is no penalty for guessing, so it is advisable not to leave any
answer blank. A minimun score of 720 out of 1000 is required to to pass. This exam is challenging, thorough preparation and practice are essential for success.
To Register, create the account on the AWS certification
site. The exam can be taken online via OnVUE or in-person at a test center. I took my exam at a test center and highly recommend this option to minimize
distractions that might occur at home. Below are some of my best-known methods (BKMs).
- Understanding why incorrect (distractor) answers are wrong is crucial. Begin by eliminating these options first.
- If you are not completely certain about an answer, flag the question and return to it later for review.
- One of my tricks is to preview the choices before fully reading each question. This approach provides additional insight and context.
Material
Note
I successfully passed the exam with score exceeding 810 in my first attempt. AWS dispatches your score and results within 7 working days—though I received mine in just 2 days. You
can also download your score report in exam register portal. The report not only show result but your score performance percentage in each domain.
Digital badge issued with expiration for 3 years. An additional benefit for passing exam is AWS provides 50% discount on your next exam. Don't forget to claim it.

AWS ML Specialty certification
The AWS Certified Machine Learning – Specialty certification is an advanced certification offered by Amazon Web Services that validates your ability
to design, implement, deploy, and maintain Machine Learning (ML) solutions for given business problems. It demonstrates the candidate's expertise in using AWS
services to design and create ML solutions that are scalable and efficient.
Exam content domain include Data Engineering, Exploratory Data Analysis, Modeling and
ML implementation. Around 50% of the exam content on the ML concept eg: handle missing/un-balanced data, evaluating performance, model tuning. And the other
50% of content on AWS ML offering and best practices eg: SageMaker, data ingest in AWS, AI services, custom Algorithm.
Machine learning and artificial intelligence
are rapidly evolving fields to a wide array of industries, this certification ensures your professionals skills are up-to-date with the latest ML technologies
with AWS cloud.
How do I prepare
My years of experience working with customers on data and AI workloads for training and inference have fortified my skills in AI and ML, which I believed would
align well with the content of the related certification exams. Indeed, my background facilitated a quicker grasp of key concepts, such as employing
a confusion matrix for classification tasks and using metrics like recall, precision, accuracy, or the F1 score to measure model performance. Delving deeper into
model tuning, I dedicated time to understanding underfitting and overfitting, hyperparameter optimization, and data manipulation to meet specific metric criteria.
The "AWS Certified Machine Learning Specialty" course on Udemy, presented by Frank Kane and Stephane Maarek, was an good resource that bolstered my
understanding of AWS ML concepts. Frank's lecture on SageMaker and AWS ML services and operations were particularly enlightening. A significant portion of my
study time was invested in under the hood of SageMaker algorithms and exploring the technical nuances of SageMaker tools such as Canvas, Data Wrangler,
and Autopilot, all of which offered extensive hands-on experience. I highly recommend becoming well-acquainted with these algorithms and toolkits,
as they are integral to the exam.
Additional resources I found exceptionally helpful include the AWS blog and
the AWS Architecture Center. The newly posted blog on ML usage scenarios
provides a more insightful perspective on potential solutions to keep learning more interesting.
Specifically to the exam, frequent practice increases your chances of passing the exam.
The AWS Skill Builder offers practice exams that are instrumental in
familiarizing yourself with the format and types of questions you'll encounter. Similar practice exams are available on Udemy as well.
Aim to score above 800 on your practice exam, review your answers, and take notes on the practice exams to solidify your understanding and readiness for the actual exam.
Exam experience
The exam lasts 180 minutes and costs $300. It comprises 65 questions, which are either multiple-choice to select one correct answer out of four
or multiple-response where two or more answers must be selected from five options. There is no penalty for guessing, so it is advisable not to leave any
answer blank. A minimun score of 750 out of 1000 is required to to pass. This exam is in advanced spacialty level which even more challenging.
Thorough preparation and practice are essential for success.
To Register, same web portal as my previous AWS SA exam to log-in and register. Create the account if you are new to AWS exam on the AWS certification
site. The exam can be taken online via OnVUE or in-person at a test center. I took my exam at a test center and highly recommend this option to minimize
distractions that might occur at home. Below are some of my best-known methods (BKMs).
- Understanding why incorrect (distractor) answers are wrong is crucial. Begin by eliminating these options first.
- If you are not completely certain about an answer, flag the question and return to it later for review. I marked more questions in this exam as distractor
are not so obvious to eliminate.
- One of my tricks is to preview the choices before fully reading each question. This approach provides additional insight and context.
Material
Note
I opted to reschedule my first certification exam as I don't feel highly confidence in such 3-hour rigorous exam. it paid off when
I successfully passed the exam with score exceeding 800 in my first attempt. AWS dispatches your score and results within 7 working days—though I received mine in
just 2 days. You can also download your score report in exam register portal. The report not only show result but your score performance percentage in each domain.
Digital badge issued with expiration for 3 years. An additional benefit for passing exam is AWS provides 50% discount on your next exam. Don't forget to claim it.
Remember to clean up your AWS services and environment after completing your hands-on sessions to avoid unnecessary costs. Be aware that some of the ML
services are not included in the free-tier. Setting up budget alerts and disabling unnecessary services are crucial lessons I learned while preparing for this exam.

GCP Professional Cloud Architect certification
The Google Cloud Professional Cloud Architect (PCA) certification is a prestigious credential offered by Google Cloud to validate an individual's ability to
design, develop, and manage robust, secure, scalable, highly available, and dynamic solutions to drive business objectives on Google Cloud Platform (GCP).
GCP has integrated Google Workspace and the Vertex AI platform to boost collaborative and advanced AI capabilities, attracting more customers to the GCP cloud.
This integration provides a competitive edge in the rapidly evolving cloud computing domain.
How do I prepare
I leveraged my experience with AWS hybrid-cloud services to broaden my knowledge in GCP. Both platforms share similar concepts in cloud infrastructure components,
such as compute instances, VMs, storage, databases, networking, and containers, though their implementations differ. For example, creating a new VM on both GCP and
AWS involves similar configurations for instance type, image, storage, and networking. Despite significant differences in APIs and console interfaces, the underlying
cloud concepts remain similar, which accelerated my learning curve in GCP. I found the comparison
of AWS and Azure Services to Google Cloud particularly helpful in comparing different services between GCP and AWS.
Google Cloud training offers a diverse content of learning resources, including videos, documents,
and labs, providing an excellent jumpstart. The labs grant temporary credentials to log into GCP for learning purposes, ensuring that there is no risk to your
personal account or unexpected charges. I began with the Cloud Architect learning path on the
GCP Skill Boost
site, completing courses earns you points and viewing your position on the leaderboard adds more fun and motivational element to my learning experience.
To explore the breadth and scope of the domains covered in the exam, the Preparing
for the Architect Journey course offers diagnostic questions that are instrumental in familiarizing yourself with the format and types of questions you'll
encounter. Review your answers and take notes on these diagnostic questions to solidify your understanding and readiness for the actual exam. Another good
resource is the Cloud Architecture Center, which provides design guides
and reference architectures that are quite helpful in my learning.
Exam experience
The exam lasts 120 minutes and costs $200. It consists of 50-60 multiple-choice and multi-select questions, as outlined in the exam guide. In my exam session,
however, I encountered only 50 multiple-choice questions, each with one correct answer out of four options. There is no penalty for guessing, so it is advisable
not to leave any answers blank. A minimum score of 800 out of 1000 is required to pass.
To Register exam, create the account on the Weassesor
site. The exam can be taken remote proctored or onsite proctored in the test center close to you.
I took my exam at a test center and highly recommend this option to minimize distractions that might occur at home. Below are some of my best-known methods (BKMs).
- Understanding why incorrect (distractor) answers are wrong is crucial. Begin by eliminating these options first.
- If you are not completely certain about an answer, flag the question and return to it later for review.
Material
Note
I successfully passed the exam on my first attempt. Unlike AWS certification, the results are displayed immediately after completing and submitting the exam,
providing a straightforward way to know the outcome without the delay of waiting for days. Exciting....The official report, indicating whether you passed or failed,
is sent within 7 working days.

Accelerate ZFS performance with Persistent Memory
ZFS (Zettabyte File System) is an advanced file system and logical volume manager originally designed by Sun Microsystems. Initially integrated into Sun's
Solaris Operating System, ZFS has been ported to other Unix-like systems, including FreeBSD and OpenZFS on Linux. ZFS is widely utilized in
Software-Defined Storage (SDS) for NAS (Network Attached Storage) or NFS (Network File System) storage products. This blog post explores how to enhance performance
by leveraging fast SSDs, such as persistent memory, as tiering and caching layers.
ZFS storage architecture
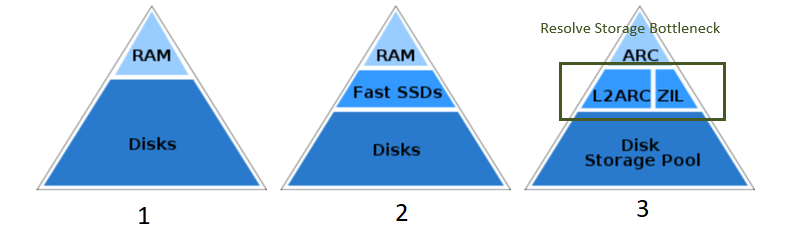
Traditional memory and storage tiering adopt a two-tier pyramid layout; memory has a smaller capacity and is closer to the CPU with nanosecond latency,
while storage disks, although positioned farther from the CPU, offer significantly larger capacity with hundred-millisecond latency (as shown in Fig. 1).
Cache misses incur substantial performance penalties by necessitating data retrieval from disk storage. Modern storage architectures incorporate additional layers,
such as fast SSDs that provide larger capacity and lower latency between memory and storage disks (as shown in Fig. 2). This mitigates the penalties associated
with memory cache misses and enhances both read and write speeds, thereby accelerating data retrieval back to the CPU. In the ZFS software stack, the ZIL
(ZFS Intent Log) and L2ARC (Level2 Adaptive Replacement Cache) serve as tiering and caching layers for synchronous write and read operations using fast SSDs (
as shown in Fig. 3).
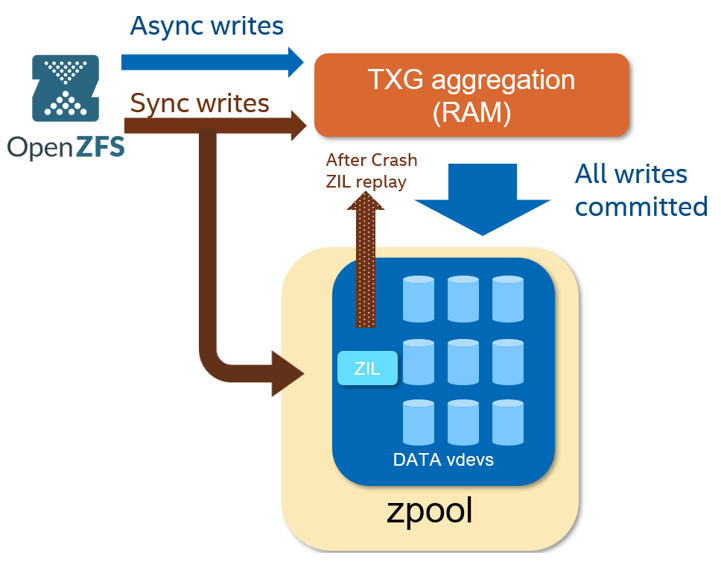
ZIL stands for ZFS Intent Log. In ZFS, the ZIL is crucial for logging synchronous operations to disk before they are written to disk-based zpool storage.
This synchronous logging ensures that operations are completed and writes are committed to persistent storage, rather than merely being cached in memory.
The ZIL functions as a persistent write buffer, facilitating quick and safe handling of synchronous operations. This is particularly important before the
spa_sync() operation, which can take considerable time to access disk-based zpool storage. Essentially, ZIL is designed to enhance the reliability and integrity
of data by processing writes more efficiently prior to long-term storage commits during spa_sync().
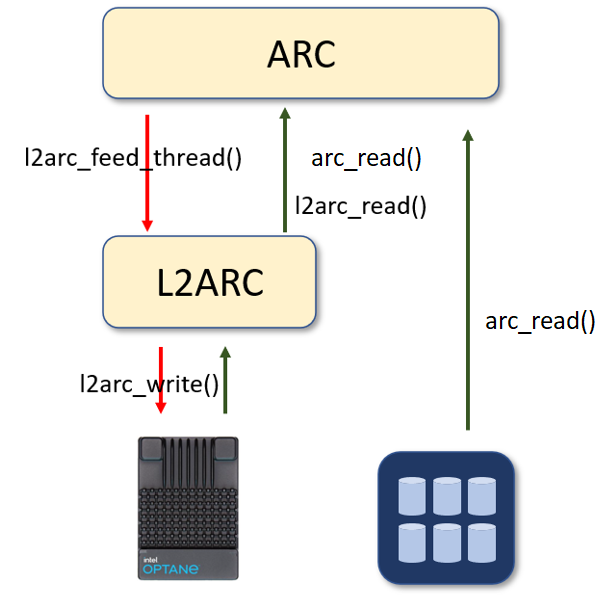
The level2 ARC is a cache layer in-between memory and disk-based zpool storage. It uses dedicated fast SSD to enlarge the cache capacity to hold cached data and
boost the random read performance. There is no eviction path from the ARC to the L2ARC, meanig ARC and L2ARC work as largher capacity of cache reduce cache-miss
. L2ARC cache the data from the ARC before it is evicted. arc_read() only read from the disk-based zpool storage when the data not exist in both ARC and L2ARC.
Performance profile
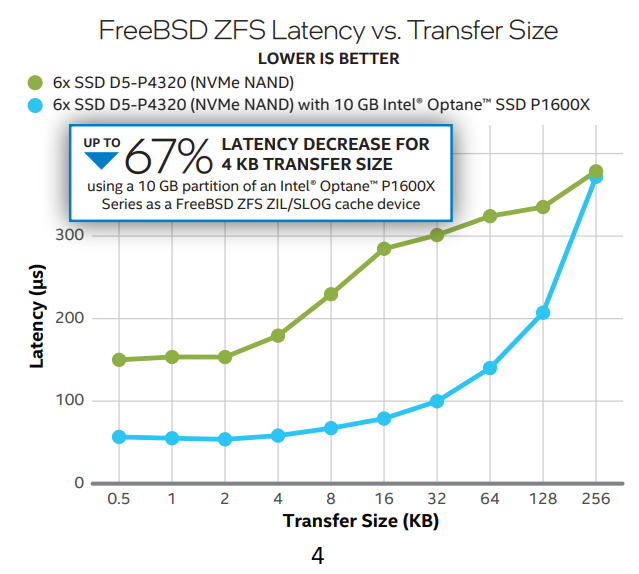
Intel Optane persistent memory SSDs, such as the P5800X and P1600X with micro-second latency, are ideal for the ZIL and L2ARC layers. In the test
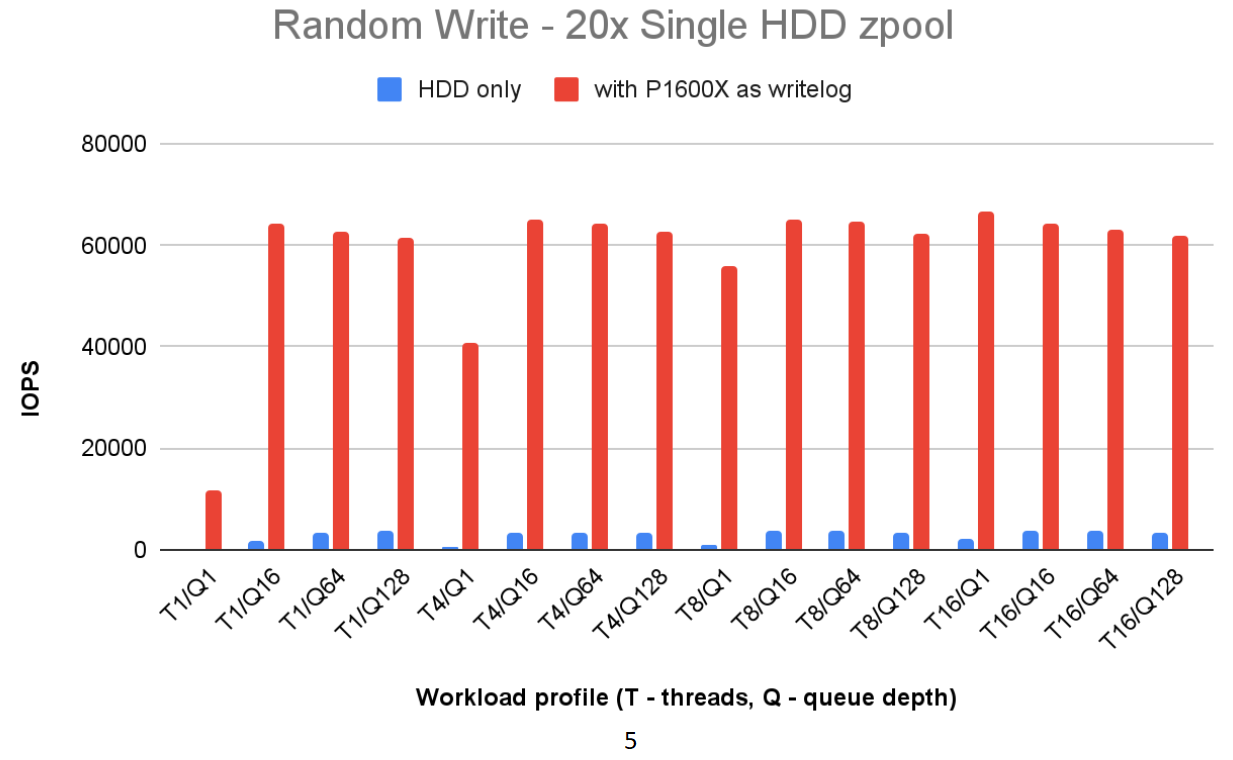
configuration (shown in Fig4) six QLC NAND SSDs configured with RAIDz2 are used as zpool storage, with a P1600X serving as the ZIL log. This setup
reduced 4Kbyte random write latency by 67%. A similar configuration that replaced the zpool storage with 20 HDDs which significantly enhanced the 4K random
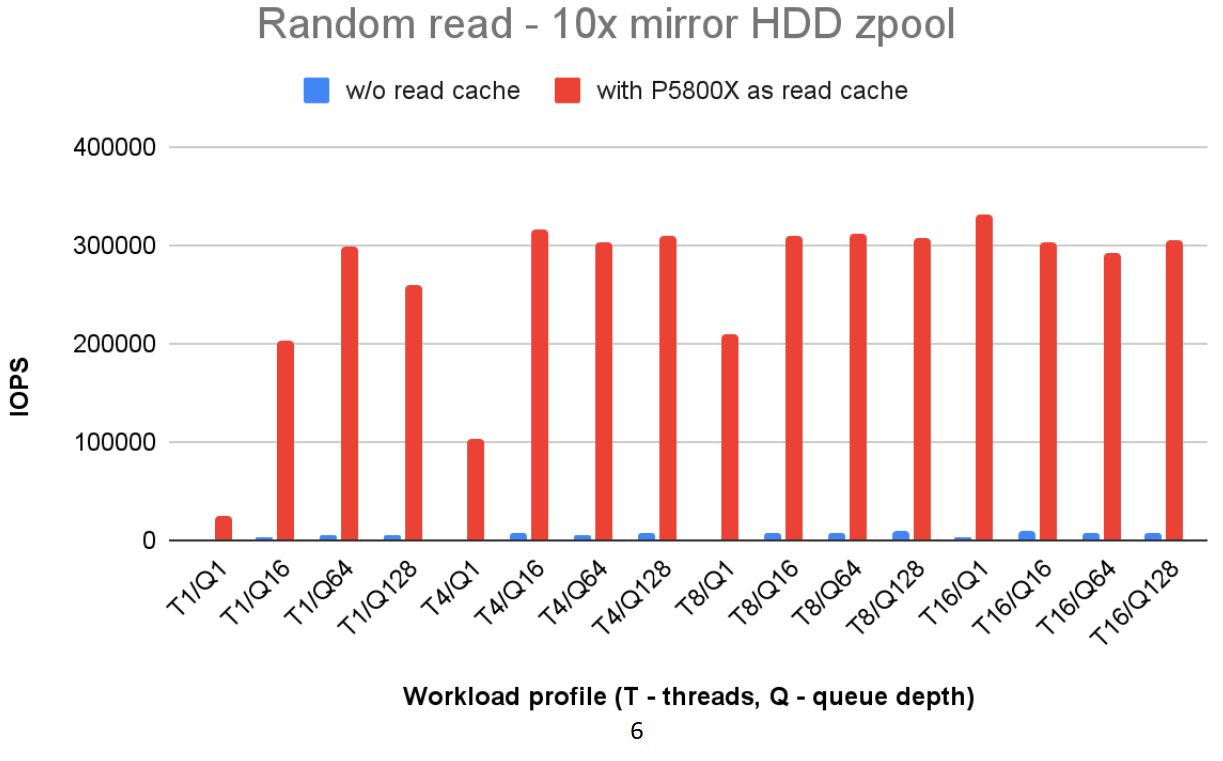
write IOPS, improving more than 100 times(as depicted in Fig5). In the data cache test scenario, with the zpool storage comprising 20 HDDs in RAID1 array and a P5800X
as the L2ARC, the random read IOPS performance also improved by more than 100 times. (shown in Fig6) The data indicates the tiering storage architecture has significantly
enhanced both read and write performance.
Reference
Well architect and profiling Datacenter NVMe SSD
Solid State Drives (SSDs) have rapidly evolved due to advancements in NAND flash media processes and interface protocols, leading to higher capacities
and lower latencies. This blog aims to provide an overview of the architectural considerations and tools necessary for adapting and profiling Datacenter
NVMe flash SSDs. Important considerations include leveraging a tiering architecture to balance Total Cost of Ownership (TCO) and performance when NAND flash
media transitions from SLC (Single-Level Cell) to more dense formats like TLC (Triple-Level Cell), QLC (Quad-Level Cell), and even PLC (Penta-Level Cell)
with endurance significantly decreases. Additionally, integrating low-latency storage software stacks such as SPDK or io_uring becomes crucial
when employing low-latency SSDs in mission-critical workloads.
NVMe SSD interface and form factor
Few key factors on NVMe SSD:
-
Interface: Modern NVMe SSDs based on PCIe 5 offer a staggering 128GT/s, providing more than 20 times the bandwidth compared to the latest SATA3
(Serial ATA) interface, which supports 6Gbit/s. NVMe SSD based on PCIe can significantly influence the performance and scalability of the storage
system. Additionally, the next-generation Compute Express Link (CXL) based on PCIe 5 can also be utilized to set up storage pooling/sharing in
heterogeneous computing environments.
-
Flash Media: As NAND flash media capacity increases with bits-per-cell, write performance does not scale similarly because the write block
size also increases. High-capacity QLC SSDs exhibit lower performance and reduced endurance in small block write workloads compared to TLC SSDs.
A tiering architecture that leverages the high performance and endurance of SLC or persistent memory combined with QLC/PLC SSDs emerges as a
genuine solution.
-
SSD Form Factor: The choice of form factor influences hardware design and backplane configurations in your server. General M.2 and U.2
form factors are commonly used in today's data centers. The new E1.s form factor by SNIA SFF-TA offers benefits in capacity, throughput,
and thermal management, positioning it as a superior replacement for M.2 and U.2 in 1U/2U servers.
Low latency storage stack
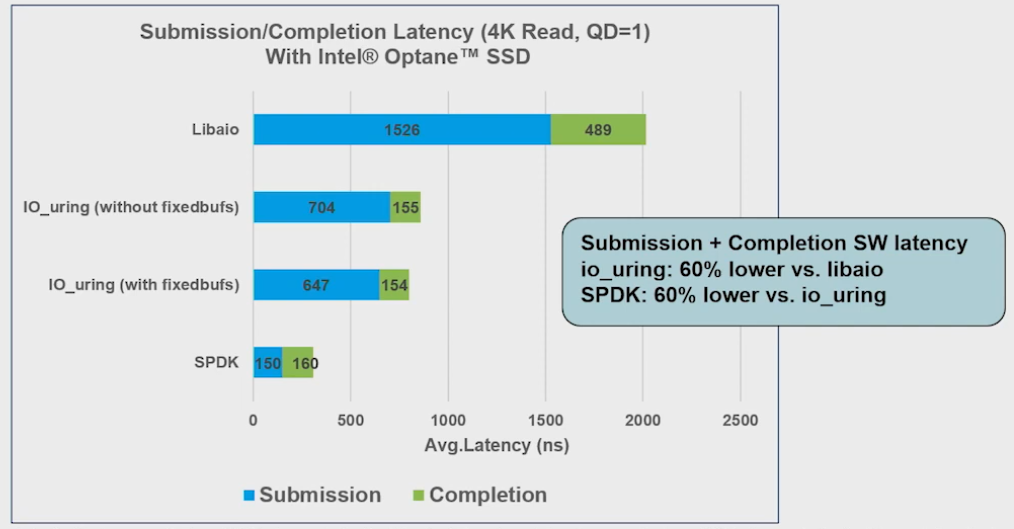
io_uring is a modern Linux I/O interface designed to reduce overhead and enhance performance. Its zero-copy and no-locking design can improve latency by
up to 60% compared to traditional asynchronous I/O methods like libaio. io_uring was introduced in Linux kernel v5.1 and is supported by benchmark applications
such as fio and t/io_uring, which have integrated io_uring capabilities. However, io_uring still relies on Linux context switches for I/O operations, which may
introduce performance penalties. In contrast, the Storage Performance Development Kit (SPDK) moves all necessary drivers into user space, leveraging polling and
avoiding system calls to achieve superior storage performance. SPDK is also widely used in RDMA and NVMe-oF disaggregated storage architectures.
The following test from SNIA shows the io_uring reduce 60% of latency compare to libaio. And SPDK reduce 60% of latency comapre to io_uring.
Performance profile
Before profiling your NVMe SSD, it is crucial to verify the SSD's health and ensure it has the correct firmware version ready for benchmarking. The open-source
tool nvme-cli is used for managing, monitoring health, and updating firmware on NVMe SSDs. A good practice is to use nvme-cli to install the latest firmware,
check the appropriate namespace for your target, and monitor health via SMART logs. Low-level formatting and pre-conditioning are recommended before initiating
benchmark workloads. Persistent memory SSDs, such as Optane, which feature highly consistent flash media, can streamline the profiling process by reducing the
need for lengthy pre-conditioning cycles.
The Flexible I/O Tester (fio) is a widely recognized and versatile tool for I/O benchmarking and stress-testing storage
systems. It supports extensive configuration options with different I/O engines, read/write ratios, and block sizes to simulate realistic workload patterns.
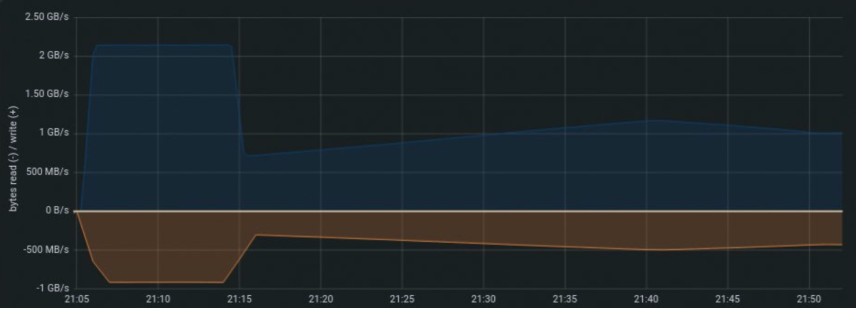
The following graph profiles a TLC NVMe SSD under a 70/30 read/write ratio and a 4K random workload over 60 minutes. It took approximately 50 minutes for the NVMe
drive to reach a steady performance state. A performance drop of about 70% was observed after 20 minutes of runtime, coinciding with the start of garbage collection
process. Ensure that the performance profiling duration is sufficient, to reach a steady state for the reliable and accurate measurements.
Reference
Observability with Grafana, Prometheus, and Intel VTune
Observability in cloud computing involves the collection and analysis of various telemetry types, such as metrics, distributed traces, and logs.
It enables the understanding and diagnosis of an internal system's state, performance, and issues without disrupting operations. Similar tools are implemented
by cloud service providers, including AWS CloudWatch, AWS CloudTrail, Google Cloud Operations, and Azure Monitor. On-premises environments often utilize tools
like Prometheus and OpenTelemetry, integrated with Grafana for the observability. Intel's oneAPI VTune is also widely adopted to address application performance bottlenecks.
This blog aims to provide a deeper insight into Prometheus, Grafana, and Intel oneAPI VTune.
Prometheus, Grafana, and Intel VTune
Prometheus is an open-source monitoring and alerting toolkit that collects and stores metrics as time-series data. It supports a variety of libraries and
servers, known as exporters, which facilitate the exporting of metrics from systems into Prometheus-compatible formats. The node_exporter is included by default
and enables hardware and OS-level metrics from the kernel, such as CPU usage, disk I/O, memory info, and network stats. Users can also create custom
exporter plugins for proprietary metrics using Golang.
Grafana is an open-source visualization and analytics platform that enables you to query, visualize, alert on, and explore your metrics, regardless of
their storage location. It transforms time-series data from Prometheus node_exporters into compelling graphs and visualizations. Grafana supports a wide
array of data sources including InfluxDB, Graphite, and Elasticsearch. Additionally, it allows for the integration of multiple data sources within the same
dashboard, facilitating a comprehensive view of data across various environments and platforms.
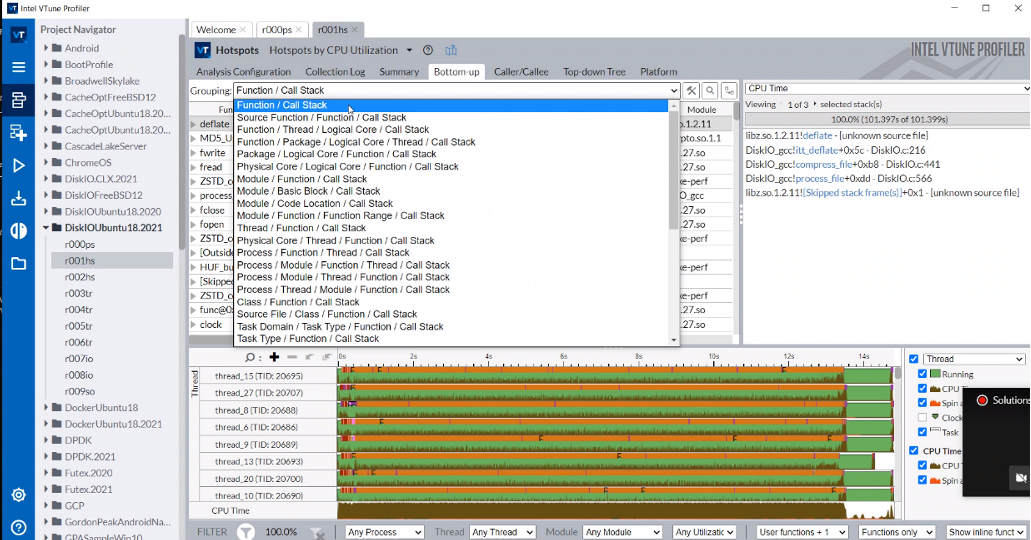
Intel VTune Profiler is a powerful tool for deep performance optimization, ensuring that software runs efficiently on hardware. It examines
application code and identifies threading issues and resource bottlenecks. VTune also analyzes code and threads hotspots that significantly impact performance.
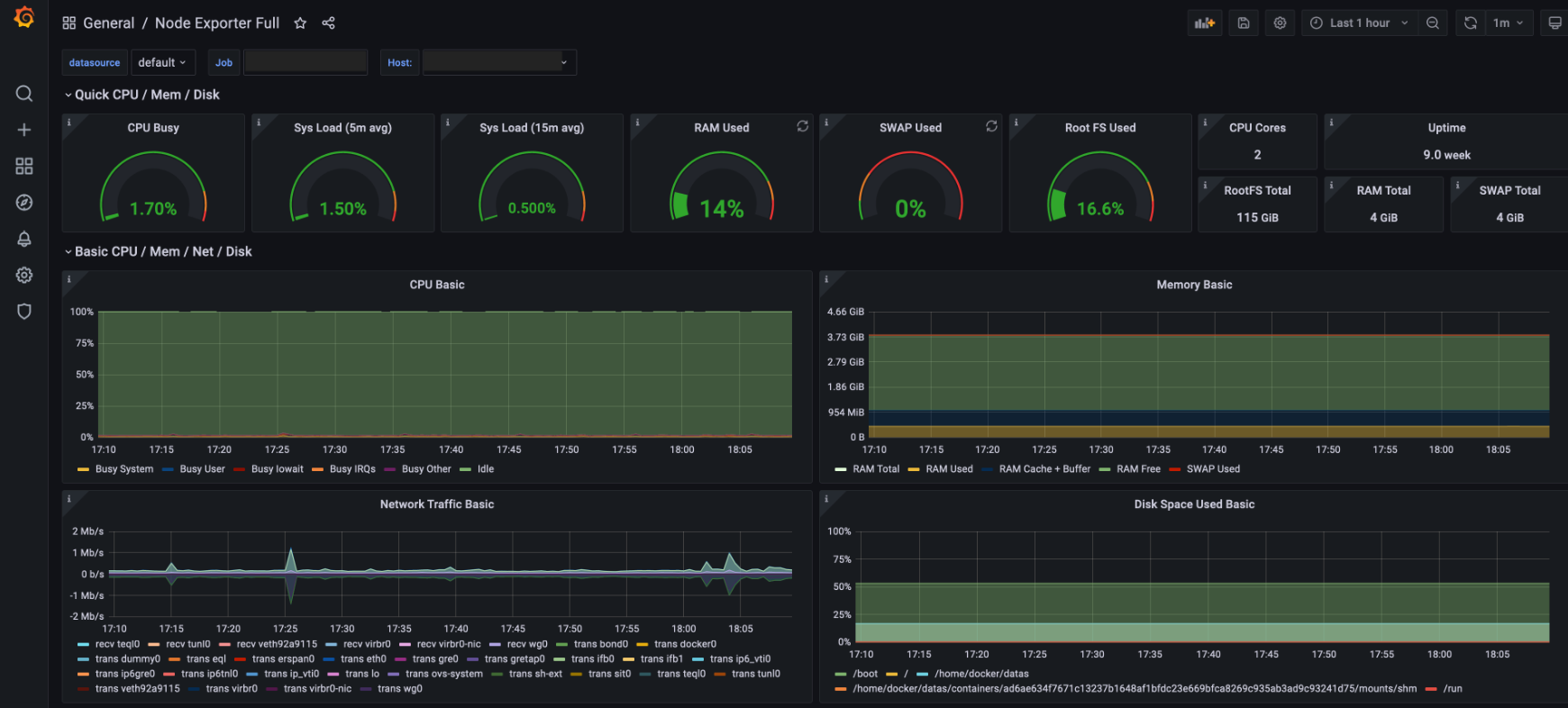
Below is a Grafana dashboard displaying metrics sourced from Prometheus, providing a visual representation. And the VTune profiler user interface
Summary
Prometheus and Grafana together deliver exceptional observability by monitoring and alerting on time-series data, enhanced by rich visualizations for
on-premises environments. Intel VTune provides in-depth analysis for application and resource performance optimization. All these open-source tools are
readily available to enhance observability in private cloud environments. In public cloud or hybrid-cloud settings, leveraging tools from cloud service providers can
significantly extend observability capabilities beyond what Grafana or VTune alone can offer.
Reference
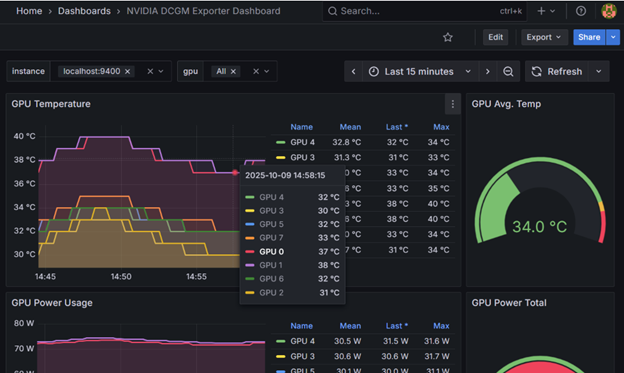
DCGM-exporter observability with NVIDIA GPU
NVIDIA Data Center GPU Manager (DCGM) is a suite of tools for managing and monitoring NVIDIA Datacenter GPUs in cluster environments. It includes active health
monitoring, comprehensive diagnostics, system alerts, and governance policies including power and clock management. DCGM also includes active and passive diagnostics
for Nvidia hardware. Administrators can access this data through a user-friendly interface or via a command-line tool, enabling them to set up alerts for any
irregularities or performance issues. By proactively identifying potential problems and optimizing GPU performance, NVIDIA DCGM plays a crucial role in maintaining the
efficiency and reliability of data center operations.
Here are step-by-steps to install DCGM and Grafana components
Install DCGM-exporter
-
DCGM-exporter exposes GPU metrics exporter for Prometheus leveraging NVIDIA DCGM. Install DCGM-exporter by following https://github.com/NVIDIA/dcgm-exporter
-
docker run -d --gpus all --cap-add SYS_ADMIN --rm -p 9400:9400 nvcr.io/nvidia/k8s/dcgm-exporter:4.4.1-4.6.0-ubuntu22.04
Check the exporter to retrieve metrics with curl
-
curl localhost:9400/metrics
Install Prometheus
-
Download/Install Prometheus by following the installation guide from site. I use the pre-compiled binary, but step also supports on the container for user preference https://prometheus.io/docs/prometheus/latest/installation/
-
Edit the Prometheus.yml and add the targets port 9400 in the static_configs for DCGM exporter before you run Prometheus
Install Grafana
-
Install Grafana by following installation https://grafana.com/docs/grafana/latest/setup-grafana/installation/
-
Download the pre-config DCGM dashboard JSON file from this site that you can just import in the Grafana. https://grafana.com/grafana/dashboards/12239-nvidia-dcgm-exporter-dashboard/ You also can configure your own dashboard for specific metrics.
-
Log-in to Grafana and add Prometheus as datasource
-
Import the DCGM dashboard in the Grafana. Grafana dashboard should show the GPU metrics from Prometheus default port 9090 which include DCGM-exporter port 9400